
I bought a used computer and put Arch Linux on it so I can have my own server. After installing nginx and fail2ban I just opened it up to the wilderness of the internet because, why not?? it’s not like I have anything important on here. What’s the worst that could go wrong?
I did not expect to see so much web traffic so quickly. I’ve spent way too long just staring at my nginx logs to see who stops by. I would say it’s mostly a 50/50 split between web scrapers/crawlers for search engines or AI training, and hackers looking for easy targets. There were also a few eccentric small public works and non-profit type internet projects few and far between.
Notable Item 1: Web Crawler Traffic for Old URLs
The first thing I noticed was that a lot of bots were pinging my domain and requesting old blog posts from the previous incarnation of the site. Very interesting that there are indexers out there that care about ancient history. 🤫
/ideas/cory-s-hobo-garden/day-6-i-made-a-bucket-with-a/ HTTP/1.1
/highlights HTTP/1.1
/highlights/ HTTP/1.1
/ideas/corys-blog/downfall-of-society/ HTTP/1.1
/ideas/emulators/the-raspberry-pi-4-compute/ HTTP/1.1
/ideas/corys-blog/wow-what-the-fuck/ HTTP/1.1
This was back when I made my own blog cms from scratch using Django. I wonder how long it will take for all these indexers to stop looking for these pages…
Notable Item 2: Lots of Automated WordPress Attackers
Hacked by Mr. Green
When I was still configuring the docker compose file, I stopped working one night and left my WordPress instance up and running at the install screen. I went to bed and wondered what would happen when I woke up.
I did this a few times, but when I left this unattended for about 24 hours, I came back to it being hacked by a “Mr. Green”.
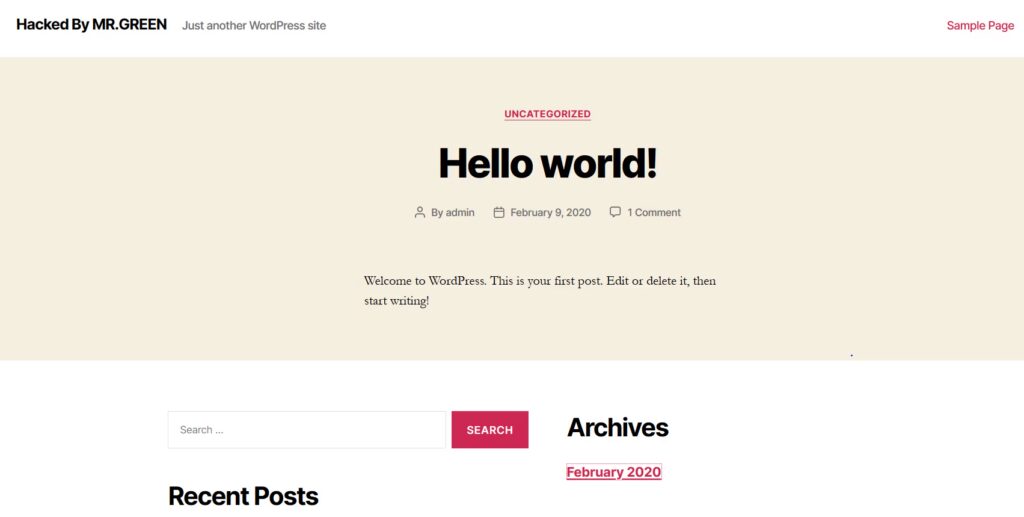
Who is Mr. Green?!? Looks like this is a very common WordPress exploiter bot that looks for uninitialized WordPress instances and steals them. I brought the docker instance down, deleted the volumes, and remade it.
So that was fun. Don’t leave your WordPress instances un-setup. That was probably pretty obvious though.
Abuse of xmlrpc.php
I did some research and it looks like xmlrpc is a file that WordPress uses to enable headless API access, but was made before modern security standards came around and never really changed. This is very commonly exploited to reroute http requests from someone’s original server through this script (so someone can use my computer as a waypoint to mask the original source address of the request). I found this page to be very helpful in explaining things.
2.58.56.48 Feb/20/2025 20:51:56 /blog/xmlrpc.php HTTP/1.1 200 413 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 - -
2.58.56.48 Feb/20/2025 20:51:57 /blog/xmlrpc.php HTTP/1.1 200 413 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 - -
2.58.56.48 Feb/20/2025 20:51:57 /blog/xmlrpc.php HTTP/1.1 200 413 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 - -
2.58.56.48 Feb/20/2025 20:51:57 /blog/xmlrpc.php HTTP/1.1 200 413 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 - -
2.58.56.48 Feb/20/2025 20:51:57 /blog/xmlrpc.php HTTP/1.1 200 413 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 - -
2.58.56.48 Feb/20/2025 20:51:57 /blog/xmlrpc.php HTTP/1.1 200 413 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 - -
//etc...
There’s literally 1000 lines of this person pinging the xmlrpc.php file in my WordPress instance. I installed a plugin to disable serving this file, since it’s not really needed unless you want to use the Android app to use WordPress.
Suspicious URI Accesses of Internal WordPress Files
And there’s a whole range of generally suspicious bots that try a ton of different paths that might yield something unsecured. For instance…
//blog/wp-includes/wlwmanifest.xml HTTP/1.1
//web/wp-includes/wlwmanifest.xml HTTP/1.1
//wordpress/wp-includes/wlwmanifest.xml HTTP/1.1
//wp/wp-includes/wlwmanifest.xml HTTP/1.1
//2020/wp-includes/wlwmanifest.xml HTTP/1.1
//2019/wp-includes/wlwmanifest.xml HTTP/1.1
//2021/wp-includes/wlwmanifest.xml HTTP/1.1
//shop/wp-includes/wlwmanifest.xml HTTP/1.1
//wp1/wp-includes/wlwmanifest.xml HTTP/1.1
//test/wp-includes/wlwmanifest.xml HTTP/1.1
//site/wp-includes/wlwmanifest.xml HTTP/1.1
//cms/wp-includes/wlwmanifest.xml HTTP/1.1
Someone tried a whole bunch of random URLs looking for a directory that contains a file called wlwmanifest.xml. Also notice the weird double slash at the beginning.
And another person trying to find if I have a phpMyAdmin instance installed. 😂
/administrator/PMA/index.php?lang=en HTTP/1.1
/administrator/PMA/index.php?lang=en HTTP/1.1
/db/index.php?lang=en HTTP/1.1
/db/index.php?lang=en HTTP/1.1
/sql/php-myadmin/index.php?lang=en HTTP/1.1
/sql/php-myadmin/index.php?lang=en HTTP/1.1
/mysql-admin/index.php?lang=en HTTP/1.1
/mysql-admin/index.php?lang=en HTTP/1.1
/phpmyadmin2021/index.php?lang=en HTTP/1.1
/phpmyadmin2021/index.php?lang=en HTTP/1.1
One guy found my actual pma index path and tried to login like 50 times…
/autodiscover/autodiscover.json?@zdi/Powershell HTTP/1.1
What the heck is this, huh??? Very sus. 🤔
This guy seems to be from Microsoft, though I’m assuming it’s probably one of their Azure tenants and not actually the organization themselves.
/lib/phpunit/phpunit/Util/PHP/eval-stdin.php HTTP/1.1
/laravel/vendor/phpunit/phpunit/src/Util/PHP/eval-stdin.php HTTP/1.1
/zend/vendor/phpunit/phpunit/src/Util/PHP/eval-stdin.php HTTP/1.1
/wp HTTP/1.1
/wp HTTP/1.1
/bc HTTP/1.1
/bc HTTP/1.1
/bk HTTP/1.1
/bk HTTP/1.1/ralphwetzel/theonionbox
And here’s more random shit people are looking for. “ralphwetzel/theonionbox”?? Nani the fuck?
//wp-login.php HTTP/1.1
Yikes! 829 back to back requests to wp-login. Get it together, fail2ban!
Notable Item 3: OpenAI and other AI/Web Crawlers
The nginx log lines have a section for requesters to put something for the user agent. Sometimes this is blank (those guys are always up to no good 😠), but most of the time, this will just be a very detailed info dump of the browser. That is, if the browser is a real person, but sometimes for bots and scrapers, you can see they put a custom string identifying their organization or bot name.
Between all the browser user agents, the custom bot strings really stand out.
OpenAI is all up in my grill, grabbing my sitemap.xml and stuff. These guys are quick. I wonder how much modern web bot traffic is from AI companies looking for more training data?
172.18.0.3 Mar/12/2025 0:55:45 /robots.txt HTTP/1.1 301 5 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot - 172.203.190.135
I swear these guys come by even more often than Google. I got no new text to ingest! No wonder everyone’s complaining about them!
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Claude is scraping me too! The least they could do is respond to my job applications…
172.18.0.3 Mar/12/2025 0:35:08 /robots.txt HTTP/1.1 301 5 Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - 87.250.224.229
I get tagged by Yandex (basically the Russian Google) quite often too. What do they want with me?!
Mozilla/5.0 (compatible; SeznamBot/4.0; +https://o-seznam.cz/napoveda/vyhledavani/en/seznambot-crawler/)
A .cz domain is… Czech Republic? They have a super cool webpage.
Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider; https://zhanzhang.toutiao.com/)
There’s a Chinese search engine as well. Bytespider scrapes me relentlessly multiple times per day.
Mozilla/5.0 (compatible;PetalBot;+https://webmaster.petalsearch.com/site/petalbot)
Here’s another crawler called PetalBot. Seem to be based in Singapore and are pretty non-threatening.
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36
BING BOT!!!
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.6943.53 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
And finally Google, which actually doesn’t seem to come around very often.
Notable Item 4: Suspicious IP Addresses from Foreign Countries
This could fill up a whole book. It’s fun taking the requestor IP address of suspicious URL requests and doing a WHOIS lookup of them. Like the xmlrpc abuser, for instance:
organisation: ORG-SG394-RIPE
org-name: 1337 Services GmbH
country: DE
org-type: LIR
address: Ludwig-Erhard-Str. 18
address: 20459
address: Hamburg
address: GERMANY
“1337 Services GmbH“…? 🤨 Okay definitely a script kiddie. That’s a ridiculous company name. Probably some teenager in his parent’s house. 😂
Other IP addresses lead back to Ali Cloud (Alibaba’s cloud hosting), other places in China, Russia, more GmbH’s, and surprisingly enough, lots of places use hosting in the Netherlands too.
Found a couple random lines with a funny user agent:
Hello World/1.0
Huh? 🤨 Who the heck is this? Sus af. Check out their WHOIS.
Mozilla/5.0 (compatible; ModatScanner/1.0; +https://modat.io/)
Modat looks like a cyber security company in Canada sniffin’ around these parts.
Notable Item 5: Suspicious IP Addresses from My Own Backyard
Doing the same WHOIS lookup also provided a good portion of suspicious activity from local cloud providers too, like AWS, GCP, and Azure.
Not to say that those services are bad, but as they are the most popular cloud hosting services, it is quite inevitable to see lots of traffic from them.
It’s very funny though. If I ever need to do something shady, I can rest assured that a cloud hosting provider will be able to host me.
Notable Item 6: “Mozlila”
No, not “Mozilla”, the Firefox web browser. Mozlila.
Mozlila/5.0 (Linux; Android 7.0; SM-G892A Bulid/NRD90M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/60.0.3112.107 Moblie Safari/537.36
Mozlila/5.0 (Linux; Android 7.0; SM-G892A Bulid/NRD90M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/60.0.3112.107 Moblie Safari/537.36Team Anon Force
Both not only have “Mozlila” in the string, but “Moblie Safari” as well. And the second type ends with “Team Anon Force”. Haha, yeah that definitely sounds like they are up to no good.
This user agent actually comes by really frequently. Mf’ers trying to trick sysadmins with poor eyesight!
This page explains everything really well. Seems like a typo in a python library led to the unique Mozlila moniker, where the original intention was to spoof a legitimate Mozilla browser user. The python library is widely used by people writing their own bots and scrapers, so a “Mozlila” user agent will have a high chance of being a malicious user.
Notable Item 7: Law Abiding Organizations and Non Profits
Across the street from me, I get scraped a few times a week by Palo Alto Networks:
Expanse, a Palo Alto Networks company, searches across the global IPv4 space multiple times per day to identify customers' presences on the Internet. If you would like to be excluded from our scans, please send IP addresses/domains to: scaninfo@paloaltonetworks.com
Of course Silicon Valley would be the origin of a bunch of activity. I really like that they put a whole disclaimer in their user agent.
Mozilla/5.0 (compatible; GenomeCrawlerd/1.0; +https://www.nokia.com/genomecrawler)
Nokia has a project called “Genome Crawler“? The page says:
Deepfield Secure Genome® is a “security map” of the internet that provides context for IP addresses, applications, and services.
That’s pretty cool. 🤔
Some company called Censys:
Mozilla/5.0 (compatible; CensysInspect/1.1; +https://about.censys.io/)
This is a cyber security company founded by CS people at University of Michigan. Cool beans.
CCBot/2.0 (https://commoncrawl.org/faq/)
This is cool! I found the first non profit that came knocking on my door. Common Crawl says they’re making a copy of the internet to provide data for researchers.
Mozilla/5.0 (compatible; InternetMeasurement/1.0; +https://internet-measurement.com/)
This is an eccentric initiative called Internet Measurement, which seems to be dedicated to spelunking open services across the web. They seem pretty innocent and are based in London, I guess. Very punk, nice nice.
Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/)
Mj12bot, a proclaimed “good bot”. Another UK based crawler.
Security Measures Inspired by this Endeavor
Previously, if I was just dumping a web app onto cloud hosting, I would not have been very interested in mucking about with traffic logs or environment details. But since I have more control over the server, I’ve suddenly found a renewed interest in cyber security.
Initially, I only protected everything with fail2ban, as suggested by some WordPress docker guides. It is pretty basic regular expression matcher that looks at your logs and bans IP addresses based on that.
I’ve since switched to something called CrowdSec, which is a much more sophisticated, albeit complex solution. This thing was pretty difficult and arduous to set up but the monitoring and attack scenario protection is very much worth it. It also comes with Metabase dashboards for monitoring alerts and events in a nice GUI with charts and diagrams and everything. I highly recommend this if you end up self-hosting for whatever reason.
Note to Self…
This gives me an idea for a game or web app, where you have a “web address/house” and it tracks the different bots and scrapers that ping the domain and then you can log in and see your “visitors” in video game avatar form and read their HTTP requests as little messages and greetings.